

Masa Depan Deep Learning Dapat Dipecah Menjadi 3 Paradigma Pembelajaran Ini

Masa Depan Deep Learning Dapat Dipecah Menjadi 3 Paradigma Pembelajaran Ini
Hibrida, Gabungan, & Pembelajaran Berkurang
Situs web asli:
Pembelajaran mendalam adalah bidang yang luas, berpusat di sekitar algoritme yang bentuknya ditentukan oleh jutaan atau bahkan miliaran variabel dan terus-menerus diubah — jaringan saraf. Tampaknya setiap hari sejumlah besar metode dan teknik baru sedang diusulkan.
Namun secara umum, pembelajaran mendalam di era modern dapat dipecah menjadi tiga paradigma pembelajaran yang mendasar. Di dalam masing-masing terletak pendekatan dan keyakinan terhadap pembelajaran yang menawarkan potensi dan minat yang signifikan untuk meningkatkan kekuatan dan ruang lingkup pembelajaran mendalam saat ini.
Pembelajaran hibrida — bagaimana metode pembelajaran mendalam modern dapat melintasi batas antara pembelajaran terawasi dan tanpa pengawasan untuk mengakomodasi sejumlah besar data tak berlabel yang tidak terpakai?
Pembelajaran gabungan — bagaimana model atau komponen yang berbeda dapat dihubungkan dalam metode kreatif untuk menghasilkan model komposit yang lebih besar daripada jumlah bagian-bagiannya?
Pembelajaran berkurang — bagaimana ukuran dan aliran informasi model dapat dikurangi, baik untuk tujuan kinerja dan penerapan, sambil mempertahankan daya prediksi yang sama atau lebih besar?
Masa depan pembelajaran mendalam terletak pada ketiga paradigma pembelajaran ini, yang masing-masing sangat saling berhubungan.
Pembelajaran Hibrida
Paradigma ini berusaha untuk melintasi batas antara pembelajaran yang diawasi dan tidak diawasi. Ini sering digunakan dalam konteks bisnis karena kurangnya dan tingginya biaya data berlabel. Intinya, pembelajaran hybrid adalah jawaban atas pertanyaan,
Bagaimana saya bisa menggunakan metode yang diawasi untuk memecahkan/berhubungan dengan masalah yang tidak diawasi?
Pertama, pembelajaran semi-terawat mendapatkan tempat di komunitas pembelajaran mesin karena mampu berkinerja sangat baik pada masalah yang diawasi dengan sedikit data berlabel. Misalnya, GAN (Generative Adversarial Network) semi-diawasi yang dirancang dengan baik mencapai akurasi lebih dari 90% pada set data MNIST setelah melihat hanya 25 contoh pelatihan.
Pembelajaran semi-terawat dirancang untuk kumpulan data di mana ada banyak data yang tidak diawasi tetapi sejumlah kecil data yang diawasi. Sedangkan secara tradisional model pembelajaran yang diawasi akan dilatih pada satu bagian dari data dan model yang tidak diawasi yang lain, model semi-terawasi dapat menggabungkan data berlabel dengan wawasan yang diekstraksi dari data yang tidak berlabel.
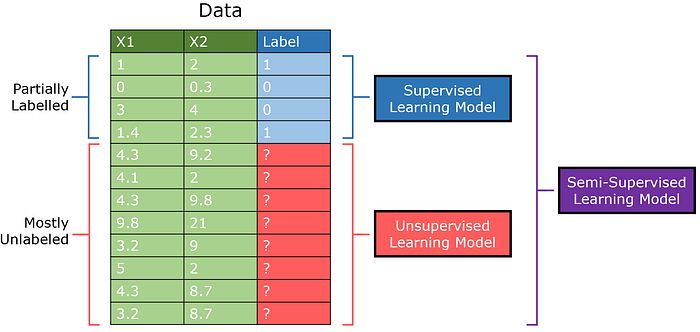
GAN semi-diawasi (disingkat SGAN), merupakan adaptasi dari standar Model Jaringan Permusuhan Generatif. Diskriminator keduanya mengeluarkan 0/1 untuk menunjukkan apakah suatu gambar dihasilkan atau tidak, tetapi juga mengeluarkan kelas item tersebut (pembelajaran multioutput).
Ini didasarkan pada gagasan bahwa melalui diskriminator yang belajar membedakan antara gambar nyata dan gambar yang dihasilkan, ia dapat mempelajari strukturnya tanpa label konkret. Dengan penguatan tambahan dari sejumlah kecil data berlabel, model semi-diawasi dapat mencapai kinerja terbaik dengan jumlah data yang diawasi minimal.
Anda dapat membaca lebih lanjut tentang SGAN dan pembelajaran semi-diawasi di sini.
GAN juga terlibat dalam area pembelajaran hybrid lainnya — diawasi sendiri pembelajaran, di mana masalah yang tidak diawasi secara eksplisit dibingkai sebagai yang diawasi. GAN secara artifisial membuat data yang diawasi melalui pengenalan generator; label dibuat untuk mengidentifikasi gambar nyata/yang dihasilkan. Dari premis yang tidak diawasi, tugas yang diawasi telah dibuat.
Atau, pertimbangkan penggunaan model encoder-decoder untuk kompresi. Dalam bentuknya yang paling sederhana, mereka adalah jaringan saraf dengan sejumlah kecil node di tengah untuk mewakili semacam kemacetan, bentuk terkompresi. Dua bagian di kedua sisi adalah encoder dan decoder.
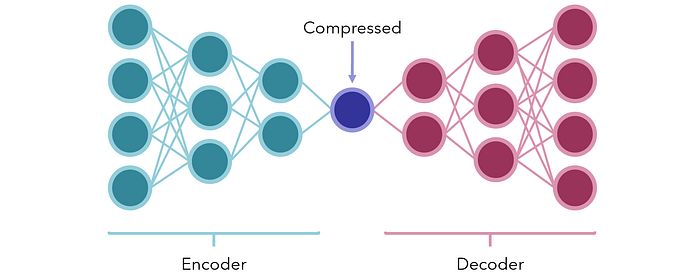
Jaringan dilatih untuk menghasilkan sama output sebagai input vektor (tugas terawasi yang dibuat secara artifisial dari data yang tidak diawasi). Karena ada hambatan yang sengaja ditempatkan di tengah, jaringan tidak dapat secara pasif meneruskan informasi; alih-alih, ia harus menemukan cara terbaik untuk mempertahankan konten input ke dalam unit kecil sehingga dapat didekodekan kembali secara wajar oleh dekoder.
Setelah dilatih, encoder dan decoder dipisahkan dan dapat digunakan pada ujung penerima data yang dikompresi atau disandikan untuk mengirimkan informasi dalam bentuk yang sangat kecil dengan sedikit atau tanpa data yang hilang. Mereka juga dapat digunakan untuk mengurangi dimensi data.
Sebagai contoh lain, pertimbangkan banyak koleksi teks (mungkin komentar dari platform digital). Melalui beberapa pengelompokan atau pembelajaran berlipat ganda metode, kita dapat menghasilkan label cluster untuk koleksi teks, kemudian memperlakukan ini sebagai label (asalkan pengelompokan dilakukan dengan baik).
Setelah setiap cluster ditafsirkan (misalnya cluster A mewakili komentar yang mengeluh tentang suatu produk, cluster B mewakili umpan balik positif, dll.) arsitektur NLP yang mendalam seperti BERT kemudian dapat digunakan untuk mengklasifikasikan teks-teks baru ke dalam kelompok-kelompok ini, semua dengan data yang sepenuhnya tidak berlabel dan keterlibatan manusia yang minimal.
Ini sekali lagi merupakan aplikasi menarik untuk mengubah tugas yang tidak diawasi menjadi tugas yang diawasi. Di era di mana sebagian besar dari semua data adalah data tanpa pengawasan, ada nilai dan potensi yang luar biasa dalam membangun jembatan kreatif untuk melintasi batas antara pembelajaran yang diawasi dan tidak diawasi dengan pembelajaran hibrida.
Pembelajaran Gabungan
Pembelajaran komposit berusaha untuk memanfaatkan pengetahuan bukan dari satu model tetapi dari beberapa. Ini adalah keyakinan bahwa melalui kombinasi unik atau suntikan informasi — baik statis maupun dinamis — pembelajaran yang mendalam dapat terus-menerus masuk lebih dalam dalam pemahaman dan kinerja daripada satu model.
Pembelajaran transfer adalah contoh nyata dari pembelajaran komposit, dan didasarkan pada gagasan bahwa bobot model dapat dipinjam dari model yang telah dilatih sebelumnya pada tugas serupa, kemudian disesuaikan pada tugas tertentu. Model yang sudah terlatih seperti Lahirnya atau VGG-16 dibangun dengan arsitektur dan bobot yang dirancang untuk membedakan antara beberapa kelas gambar yang berbeda.
Jika saya melatih jaringan saraf untuk mengenali hewan (kucing, anjing, dll.), Saya tidak akan melatih jaringan saraf konvolusi dari awal karena akan memakan waktu terlalu lama untuk mencapai hasil yang baik. Sebagai gantinya, saya akan mengambil model pra-pelatihan seperti Inception, yang telah menyimpan dasar-dasar pengenalan gambar, dan melatih beberapa epoch tambahan pada dataset.
Demikian pula, penyisipan kata dalam jaringan saraf NLP, yang memetakan kata secara fisik lebih dekat ke kata lain dalam ruang penyisipan tergantung pada hubungannya (misalnya 'apel' dan 'oranye' memiliki jarak yang lebih kecil daripada 'apel' dan 'truk'). Penyematan yang telah dilatih sebelumnya seperti GloVe dapat ditempatkan ke dalam jaringan saraf untuk memulai dari pemetaan kata yang efektif hingga entitas numerik dan bermakna.
Kurang jelas, persaingan juga dapat merangsang pertumbuhan pengetahuan. Pertama, Generative Adversarial Networks meminjam dari paradigma pembelajaran komposit dengan secara fundamental mengadu dua jaringan saraf satu sama lain. Tujuan generator adalah untuk mengelabui diskriminator, dan tujuan diskriminator tidak untuk ditipu.
Persaingan antar model akan disebut sebagai 'pembelajaran permusuhan', jangan disamakan dengan jenis pembelajaran permusuhan lain yang mengacu pada merancang input berbahaya dan mengeksploitasi batasan keputusan yang lemah dalam model.
Pembelajaran permusuhan dapat merangsang model, biasanya dari jenis yang berbeda, di mana kinerja model dapat direpresentasikan dalam kaitannya dengan kinerja orang lain. Masih banyak penelitian yang harus dilakukan di bidang pembelajaran permusuhan, dengan jaringan permusuhan generatif sebagai satu-satunya penciptaan subbidang yang menonjol.
Pembelajaran kompetitif, di sisi lain, mirip dengan pembelajaran permusuhan, tetapi dilakukan pada skala node-by-node: node bersaing untuk mendapatkan hak untuk menanggapi subset dari data input. Pembelajaran kompetitif diimplementasikan dalam 'lapisan kompetitif', di mana satu set neuron semuanya sama, kecuali untuk beberapa bobot yang didistribusikan secara acak.
Setiap vektor bobot neuron dibandingkan dengan vektor input dan neuron dengan kemiripan tertinggi, neuron 'winner take all', diaktifkan (output = 1). Yang lainnya 'dinonaktifkan' (output = 0). Teknik tanpa pengawasan ini adalah komponen inti dari peta yang mengatur sendiri dan penemuan fitur.
Contoh lain yang menarik dari pembelajaran komposit adalah dalam pencarian arsitektur saraf. Dalam istilah yang disederhanakan, jaringan saraf (biasanya berulang) dalam lingkungan pembelajaran penguatan belajar menghasilkan jaringan saraf terbaik untuk kumpulan data — algoritme menemukan arsitektur terbaik untuk Anda! Anda dapat membaca lebih lanjut tentang teori di sini dan implementasi dengan Python di sini.
Metode ensemble juga merupakan bahan pokok dalam pembelajaran komposit. Metode ansambel yang dalam telah terbukti sangat efektif, dan susun model ujung ke ujung, seperti encoder dan decoder, semakin populer.
Sebagian besar pembelajaran komposit mencari cara unik untuk membangun hubungan antara model yang berbeda. Hal ini didasarkan pada gagasan bahwa,
Sebuah model tunggal, bahkan yang sangat besar, berkinerja lebih buruk daripada beberapa model/komponen kecil, masing-masing didelegasikan untuk berspesialisasi dalam sebagian tugas.
Misalnya, pertimbangkan tugas membangun chatbot untuk restoran.

Kita dapat membaginya menjadi tiga bagian yang terpisah: basa-basi/chat-chat, pencarian informasi, dan tindakan, dan merancang model untuk mengkhususkan masing-masing. Atau, kita dapat mendelegasikan model tunggal untuk melakukan ketiga tugas.
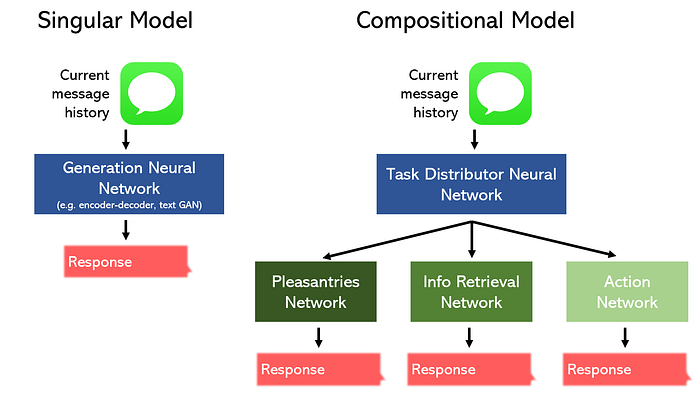
Seharusnya tidak mengherankan bahwa model komposisi dapat tampil lebih baik sambil mengambil lebih sedikit ruang. Selain itu, topologi nonlinier semacam ini dapat dengan mudah dibangun dengan alat seperti: Keras’ functional API.
Untuk memproses peningkatan keragaman tipe data, seperti video dan data 3 dimensi, peneliti harus membangun model komposisi yang kreatif
Baca lebih lanjut tentang pembelajaran komposisi dan masa depan di sini.
Pembelajaran yang Dikurangi
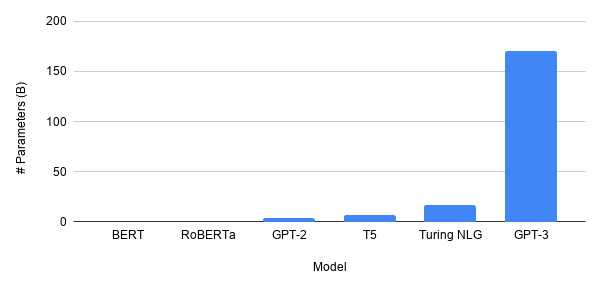
Ukuran model, khususnya di NLP — pusat kegembiraan yang terburu-buru dalam penelitian pembelajaran mendalam — tumbuh, oleh banyak. Model GPT-3 terbaru memiliki 175 miliar parameter. Bandingkan dengan BERT seperti membandingkan Jupiter dengan nyamuk (yah, tidak secara harfiah). Apakah masa depan pembelajaran mendalam lebih besar?
Sangat bisa dibilang, tidak. Memang, GPT-3 sangat kuat, tetapi telah berulang kali ditunjukkan di masa lalu bahwa 'sains yang berhasil' adalah yang memiliki dampak terbesar pada kemanusiaan. Setiap kali akademisi menyimpang terlalu jauh dari kenyataan, biasanya memudar menjadi ketidakjelasan. Ini adalah kasus ketika jaringan saraf dilupakan pada akhir 1900-an untuk waktu yang singkat karena hanya ada sedikit data yang tersedia sehingga ide tersebut, betapapun cerdiknya, tidak berguna.
GPT-3 adalah model bahasa lain, dan dapat menulis teks yang meyakinkan. Dimana aplikasinya? Ya, itu bisa menghasilkan, misalnya, jawaban atas kueri. Namun, ada cara yang lebih efisien untuk melakukan ini (misalnya melintasi grafik pengetahuan dan menggunakan model yang lebih kecil seperti BERT untuk menghasilkan jawaban).
Tampaknya tidak demikian halnya bahwa ukuran besar GPT-3, belum lagi model yang lebih besar, layak atau perlu diberikan mengeringkan dari daya komputasi.
"Hukum Moore agak kehabisan tenaga."
- Satya Nadella, CEO Microsoft
Sebagai gantinya, kami bergerak menuju dunia yang disematkan AI, di mana kulkas pintar dapat secara otomatis memesan bahan makanan dan drone dapat menavigasi seluruh kota sendiri. Metode pembelajaran mesin yang kuat harus dapat diunduh ke PC, ponsel, dan chip kecil.
Ini membutuhkan AI yang ringan: membuat jaringan saraf lebih kecil sambil mempertahankan kinerja.
Ternyata, secara langsung atau tidak langsung, hampir segala sesuatu dalam penelitian pembelajaran mendalam berkaitan dengan pengurangan jumlah parameter yang diperlukan, yang berjalan seiring dengan peningkatan generalisasi dan karenanya, kinerja. Misalnya, pengenalan lapisan konvolusi secara drastis mengurangi jumlah parameter yang dibutuhkan jaringan saraf untuk memproses gambar. Lapisan berulang menggabungkan gagasan waktu saat menggunakan bobot yang sama, memungkinkan jaringan saraf untuk memproses urutan dengan lebih baik dan dengan lebih sedikit parameter.
Embedding layer secara eksplisit memetakan entitas ke nilai numerik dengan makna fisik sehingga beban tidak ditempatkan pada parameter tambahan. Dalam satu interpretasi, Keluar lapisan secara eksplisit memblokir parameter dari operasi pada bagian tertentu dari input. Regularisasi L1/L2 memastikan jaringan menggunakan semua parameternya dengan memastikan tidak ada yang tumbuh terlalu besar dan masing-masing memaksimalkan nilai informasinya.
Dengan pembuatan lapisan khusus, jaringan membutuhkan lebih sedikit parameter untuk data yang lebih kompleks dan lebih besar. Metode lain yang lebih baru secara eksplisit berusaha untuk mengompresi jaringan.
Pemangkasan jaringan saraf berusaha untuk menghapus sinapsis dan neuron yang tidak memberikan nilai pada output jaringan. Melalui pemangkasan, jaringan dapat mempertahankan kinerjanya sambil menghapus hampir semua jaringan itu sendiri.
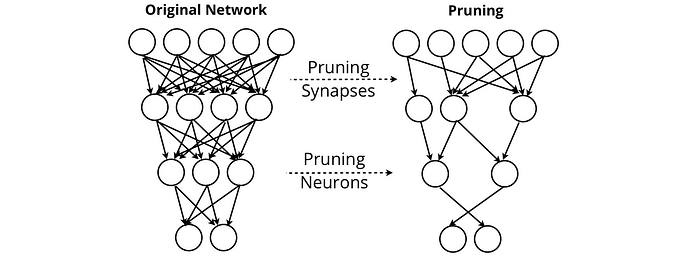
Metode lain seperti Penyulingan Pengetahuan Pasien temukan metode untuk mengompresi model bahasa besar ke dalam bentuk yang dapat diunduh ke, misalnya, ponsel pengguna. Ini adalah pertimbangan yang diperlukan untuk Sistem Terjemahan Mesin Neural Google (GNMT), yang mendukung Google Terjemahan, yang perlu membuat layanan terjemahan berkinerja tinggi yang dapat diakses secara offline.
Intinya, pengurangan pusat pembelajaran seputar desain yang berpusat pada penerapan. Inilah sebabnya mengapa sebagian besar penelitian untuk pembelajaran yang dikurangi berasal dari departemen penelitian perusahaan. Salah satu aspek dari desain yang berpusat pada penerapan bukanlah untuk secara membabi buta mengikuti metrik kinerja pada kumpulan data, tetapi untuk fokus pada potensi masalah saat model dikerahkan.
Misalnya, disebutkan sebelumnya masukan yang berlawanan adalah input berbahaya yang dirancang untuk mengelabui jaringan. Cat semprot atau stiker pada rambu-rambu dapat mengelabui mobil yang mengemudi sendiri untuk berakselerasi melebihi batas kecepatan. Bagian dari pembelajaran tereduksi yang bertanggung jawab tidak hanya membuat model cukup ringan untuk digunakan, tetapi memastikan bahwa model tersebut dapat mengakomodasi kasus sudut yang tidak terwakili dalam kumpulan data.
Pembelajaran yang dikurangi mungkin mendapatkan sedikit perhatian penelitian dalam pembelajaran mendalam, karena "kami berhasil mencapai kinerja yang baik dengan ukuran arsitektur yang layak" hampir tidak seseksi "kami mencapai kinerja canggih dengan arsitektur yang terdiri dari jutaan parameter”.
Tak pelak lagi, ketika pengejaran yang berlebihan terhadap fraksi persentase yang lebih tinggi padam, karena sejarah inovasi seperti yang ditunjukkan, pembelajaran yang berkurang — yang sebenarnya hanya pembelajaran praktis — akan menerima lebih banyak perhatian yang layak.
Ringkasan
Pembelajaran hibrida berusaha untuk melintasi batas-batas pembelajaran yang diawasi dan tidak diawasi. Metode seperti pembelajaran semi-diawasi dan self-supervised mampu mengekstrak wawasan berharga dari data yang tidak berlabel, sesuatu yang sangat berharga karena jumlah data yang tidak diawasi tumbuh secara eksponensial.
Sebagai tugas tumbuh lebih kompleks, pembelajaran komposit mendekonstruksi satu tugas menjadi beberapa komponen sederhana. Ketika komponen-komponen ini bekerja bersama — atau saling bertentangan — hasilnya adalah model yang lebih kuat.
Pembelajaran yang dikurangi belum mendapat banyak perhatian karena pembelajaran yang mendalam keluar dari fase hype, tetapi segera kepraktisan dan desain yang berpusat pada penerapan akan muncul.
Terima kasih sudah membaca!
Pernyataan: hanya untuk pertukaran akademik. Hak cipta artikel ini milik penulis asli. Jika ada yang salah, silahkan hubungi untuk menghapus.